![]()
![]()
![]()
![]()
6-й час
Основные типы данных: последовательности и словари
В предыдущей главе Вы узнали о числовых типах данных, с которыми можно работать в Python. Здесь мы продолжим изучение основных типов данных и рассмотрим последовательности (строка символов, набор, список), словари и массивы (вкратце).
Все разновидности этого типа данных отличаются от числовых типов тем, что могут использоваться двумя основными способами. Первый подход аналогичен тем приёмам, которые применяются к числам. Другими словами, можно присваивать переменным значения этих типов, после чего выполнять операции с переменной как с одним целым. Второй подход состоит в том, чтобы рассматривать их как последовательности значений, т. е. области компьютерной памяти изменяющегося размера, которыми можно оперировать как единым целым, а также вычленять из них отдельные элементы, изменять их и снова соединять вместе. В Python имеется возможность создавать последовательности числовых значений. Они называются массиВами. Есть даже стандартный модуль, который содержит средства, поддерживающие работу с массиВами. Но массивы в Python широко не используются, так как существуют альтернативные более мощные типы последовательностей, для которых разработано больше полезных функций. В конце этой главы я отведу немного времени обсуждению модуля массивов и особенностям его использования.
В Python строки символов (известны как тип strings) относятся к основным типам данных (Вы уже видели их в работе в предыдущих главах). Python определяет строки символов как "все, что угодно, заключенное в кавычки". А в кавычки можно заключать всё, что угодно. Большинство компьютерных языков однозначно разграничивает области применения различных видов символов, обозначающих кавычки. Но Python не разменивается на такие мелочи. Одинарные и двойные кавычки обрабатываются одинаково, поэтому ответ на вопрос, какой вид кавычек лучше использовать, скорее определяется вашими личными симпатиями и привычками.
*Прим. В. Шипкова: лично я из ассемблера вынес такое полезное правило - одиночные символы и строки заключать в одинарные кавычки. Чем это удобно? В России (да и зарубежом тоже) принято в тексте использовать двойные кавычки. Так вот до тех пор, пока не встречена интерпретатором закрывающая (парная) одиночная кавычка - все внутренние двойные кавычки будут считаться текстом. ИМХО, это довольно удобно. Кроме того, для выставления одинарной кавычки не нужно нажимать клавишу <Shift>. ;-)
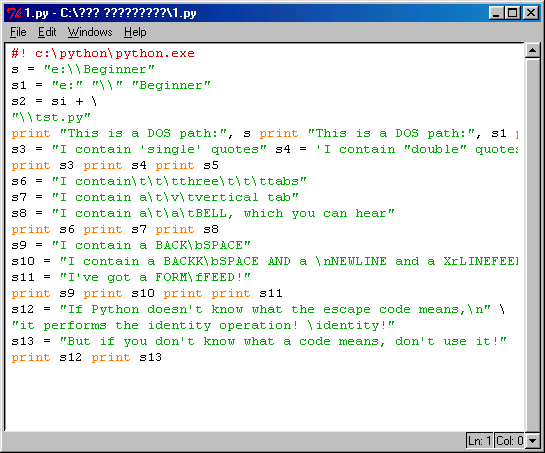
Какие символы могут стоять между кавычками? Это зависит от конкретной ситуации. Если Вы пользуетесь одинарными кавычками, то между ними можно располагать всё, что угодно, кроме одинарных кавычек. Если Вы предпочитаете двойные кавычки, то в строке нельзя использовать двойные кавычки. Конечно, имеются специальные приёмы, чтобы сообщить Python о том, что те или иные символы не являются служебным, а входят в строку. Символ обратной косой черты (\) является таким управляющим символом, который сообщает интерпретатору, что следующий за ним символ должен быть обработан не так, как обычно. В случае символа кавычки отличие заключается в том, что кавычки больше не являются признаком конца строки, а как её элемент. Немного позже Вы познакомитесь с другими управляющими символами. На рис. 6.1 показано, что произойдет, если, например, попытаться поместить одинарную кавычку внутри строки символов, выделенной такими же одинарными кавычками, а также два метода исправления этой ошибки.
Обратите также внимание на отличия, проявляющиеся в тех случаях, когда для вывода значения на печать используется инструкция print s1, s2 и когда Вы просто вводите s2 и нажимаете клавишу <Enter>. При использовании оператора print символьная строка, которую он отображает на экране, не заключается в кавычки. Дело в том, что когда Вы вводите имя переменной и нажимаете клавишу <Enter> в диалоговом режиме, Python предполагает, что Вы хотите увидеть, какое значение содержится в переменной, поэтому вставляет двойные кавычки вокруг строковых значений, чтобы напомнить Вам о типе данной переменной. Если же используется оператор print, то Python выводит только содержимое переменной, предполагая, что Вы явно укажете, если Вам нужны будут кавычки. Обратите также внимание на то, что текст, набранный национальными символами (в данном случае в кириллице), вывести в диалоговом режиме можно только командой print.
*Прим. В. Шипкова: опять же это не совсем так. Если не используется кодировка utf8 (выставляется в настройках IDLE) Вы увидите только кракозябры. Точнее, можно нормально и с другими кодировками работать, но нужно указать с какой именно.
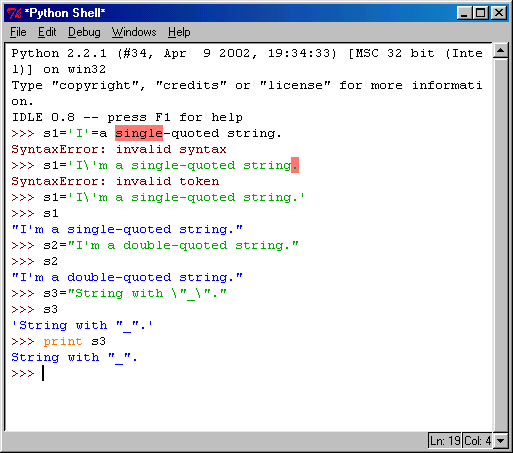
Рис. 6.1. Ввод и вывод строк, содержащих символы кавычек и буквы национального алфавита
Кроме использования символов одинарных и двойных кавычек, есть ещё третий способ разграничить строку символов, который реализуется с помощью сочетания, состоящего из трёх идущих подряд двойных или одинарных кавычек. Упоминаемые в повседневной речи как "строки символов, заключённые в тройные кавычки", или просто "тройные кавычки", они используются для того, чтобы помещать в строковые переменные многострочный текст. Чаще всего этот подход используют для создания документации функции или модуля, с чем мы познакомимся подробнее в главе 11. На рис. 6.2 показан ввод строки символов, заключённой в тройные кавычки. На этом примере Вы можете убедиться в преимуществах такого подхода использования кавычек.

Рис. 6.2. Тройные кавычки
Вывод данной строки будет отличаться в зависимости от того, просто Вы укажете переменную s, нажимая клавишу <Enter>, или используете инструкцию print. Заключение строки символов в тройные кавычки позволяет использовать в ней практически всё символы, включая символы разрыва строки и возврата каретки. Единственное исключение — в строке символов, заключенной в тройные кавычки, не должно быть трёх подряд идущих двойных кавычек. Впрочем, при необходимости можно вставить и их, предварив каждую управляющим символом обратной косой черты, как это было показано на рис. 6.1. Поскольку символ обратной косой черты внутри строки символов всегда имеет особое значение для Python, все эти значения приведены в табл. 6.1.
Таблица 6.1. Управляющие символы, используемые в строках
Символ
Назначение
\
Продолжение строки, если этот символ стоит в конце строки (он должен быть последним символом в строке, поскольку пробел в конце строки после обратной косой черты будет расценен как синтаксическая ошибка)
\\
Обратная косая черта в строке символов
\'
Одинарная кавычка в строке символов
\"
Двойная кавычка в строке символов
\а
Звуковой сигнал (команда компьютеру подать звуковой сигнал)
\b
Команда "забой символа" (аналогична нажатию клавиши <backspace>)
\е
Команда "отменить" (аналогична нажатию клавиши <Esc>; команды \033 или
\х!
В не являются управляющими символами обратной косой черты)
\0
Вставляет значение NOLL (см. текст)
\n
Вставляет символ разрыва строки (linefeed)
\v
Вставляет символ вертикальной табуляции (практически никогда не используется)
\t
Вставляет символ обычной (горизонтальной) табуляции
\r
Вставляет символ возврата каретки (carriage return)
\f
Вставляет символ разрыва страницы (form feed)
\0nn
Вставляет символ восьмеричного значения (см. текст)
\xnn
Вставляет символ шестнадцатеричного значения (см. текст)
\др
Вставляет \др. Другими словами, если значение др не совпадает ни с одним из перечисленных выше символов, Python оставляет в строке последовательность символов \др такой, как она есть. Это аналогично операции тождества в математике
Большинство из указанных выше управляющих символов Вам никогда не понадобится. Так, вертикальная табуляция сейчас практически не применяется, поскольку телетайп, для которого была предназначена эта команда, технически уже полностью устарел и почти нигде не используется. Также Вам вряд ли придётся заботиться о различиях между знаками разрыва строки, возврата каретки и разрыва страницы, если только темой вашей работы не будет перенос текстовых файлов между системами UNIX и DOS или Windows и Macintosh. А если это так, то в таком случае я уверен, Вы уже знаете более чем достаточно об этих различиях. В листинге 6.1 представлен код небольшой программы, которая демонстрирует применение некоторых наиболее распространённых управляющих символов.
*Прим. В. Шипкова: код подачи звукового сигнала вряд ли будет работать. По крайней мере, у меня точно не работает.
Листинг 6.1. Управляющие символы (программа xtst.py)
#!с:\python\python.exe
s="e:\\Beginner"
s1="e:" "\\" "Beginner"
s2=s1+\
"\\tst.py"
print "This is a DOS path:", s
print "This is a DOS path:", s1
print "This is a DOS path:", s2
s3="I contain','single' quotes"
s4="I contain "double" quotes"
s5="""I am a triple-quoted string that contains \"\"\" quotes"""
print s3
print s4
print s5
s6="I contain\t\t\tthree\t\t\ttabs"
s7="I contain a\t\v\tvertical tab"
s8="I contain a\t\a\tBELL, which you can hear"
print s6
print s7
print s8
s9="I contain a BACK\bSPACE"
s10="I contain a BACKK\bSPACE AND a \nNEWLINE and a \rLINEFNED"
sll="I've got a FORM\fFEED!"
print s9
print S10
print s11
s12="If Python doesn't know what the escape code means,\n" \
"it performs the identity operation! \identity!"
s13="But if you don't know what a code means, don't use it!"
print s12
print s13
На рис. 6.3 показан результат выполнения программы xtst.py в окне DOS, а на рис. 6.4 — результат выполнения той же программы, но уже в окне IDLE. Как видите, во втором случае управляющие символы отображаются не так, как в окне DOS.
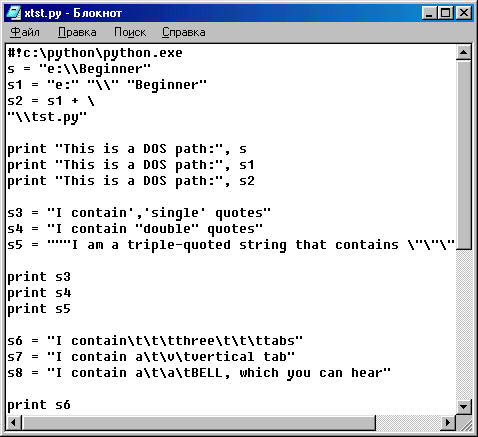
Рис. 6.3. Результат выполнения программы xtst.py в окне Блокнота

Рис. 6.4. Результат выполнения программы xtst.py в окне IDLE
Причина несовпадения символов объясняется тем, что в DOS используется расширенный набор символов ASCII. В листинге 6.2 показана ещё одна небольшая программа на языке Python (ascii.py), которая выводит таблицу символов ASCII Вашего компьютера. Ее можно выполнять на любой платформе, которая использует стандарт ASCII.
Термин ASCII является аббревиатурой от слов American Standard Code for Information Interchange (Американский стандартный код для обмена информацией). Первоначально этот стандарт предусматривал только 7-битовый код, но затем он был расширен до 8 битов. Таблица ASCII для 7-битовых кодов содержит 128 символов от 0000000 до 1111111, а таблица для 8 битовых кодов простирается до 11111111. В шестнадцатеричном виде это составляет ряд от 00 до FF.
#!с:\python\python.exe
i = 0
while i < 256 :
print chr(i)
if i != 0 and i % 8 == 0:
i = i + 1
На рис. 6.5 показано выполнение программы ascii.py в окне DOS.

Рис. 6.5. Вывод таблицы символов ASCII с помощью программы ascii.py в окне DOS
*Прим. В. Шипкова: конечно же на рисунке не окно DOS, а самый что ни на есть IDLE.
Иногда управляющие символы в тексте могут оказаться не столько полезными, сколько надоедающими. Например, в системе Windows часто бывает удобно поместить в переменную описание пути к файлу. Однако в Windows описания пути содержат символы обратной косой черты, которые служат разделителями каталогов в DOS и Windows. Необходимость вводить каждый раз этот символ дважды утомляет. Если же забыть об этом и ввести только одну обратную косую черту, то результат выполнения программы будет непредсказуем, а ошибку будет трудно найти. Для решения этой проблемы Гуидо ввёл в Python средство установки необрабатываемых строк. Чтобы сообщить Python, что данная строка символов является необрабатываемой, необходимо поместить перед ней букву "r" (r происходит от английского названия row string). Например, вот так: s = r"k:\Beginner"
Необрабатываемые строки используются и во многих других случаях, но главная причина, почему Гуидо ввёл их в Python, состоит в том, что они намного упрощают написание регулярных выражений. Без них создание регулярных выражений вылилось бы просто в титанический труд. Регулярные выражения не рассматриваются в этой книге, но Вы можете найти подробную информацию о них в Internet по адресу http://www.Python.org/.
Строки символов удобно использовать в программах, принимающих данные, вводимые пользователем с клавиатуры, для документирования работы функции или модуля, для создания дружественного пользовательского интерфейса, а также во время отладки программы. Возможно, Вы уже знаете, что те же операторы, которые мы использовали с числовыми значениями, например оператор суммирования (+), могут также использоваться для работы со строками, но при этом они выполняют другие действия. И это не случайно. Python зорко следит за типом переменных, так что в любой момент он точно знает, какой именно реакции Вы от него ожидаёте. Например, 1+1 совершенно очевидно представляет математическую инструкцию. А что подразумевается под "строка1"+"строка2"? Безусловно, знак + в данном случае означает что-то другое. В контексте строк символ + означает объединение двух последовательностей символов в одну (по-научному эта операция называется конкатенацией). Результатом действия "строка1" + "строка2" будет строка "строка1строка2". В зависимости от контекста такая возможность использовать один и тот же оператор для выполнения различных действий называется перегрузкой оператора. При умелом применении эта возможность может оказаться одним из наиболее ценных средств программирования Python. Немного позже, по мере усвоения материала, Вы научитесь выполнять перегрузку собственных операторов.
В табл. 6.2 приведён список операторов, которые можно использовать для выполнения операций над строками. Далее мы рассмотрим подробнее все эти операторы в порядке их следования в таблице.
Таблица 6.2. Операторы, используемые для обработки строк символов
Оператор
Значение
Пример
s1+s2
Конкатенация строк si и s2
s3 = s1 + s2
s*n или n* s
Многократное повторение строки — повторить строку s n раз
t = s * 5
u in s
u not in s
Является ли u элементом последовательности s или не является?
if u in s: инструкции for u in s: инструкции
s[n]
Возвращение элемента последовательности s по индексу n
z = s[0]
s[i:j]
Извлечение из строки s последовательности символов от i до j
z = s[0:2]
len(s)
Возвращение длины строки s
l = len(s)
min(s)
Возвращение минимального элемента последовательности s
m = min(s)
max(s)
Возвращение максимального элемента последовательности s
m = max(s)
Мы уже видели пример использования оператора +. Использование Оператора повторения * также вполне очевидно (рис. 6.6).
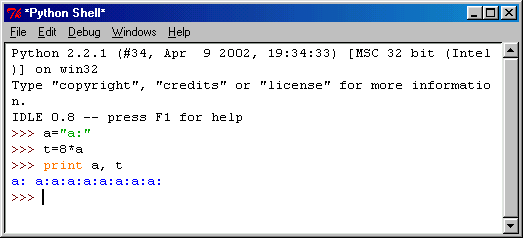
Рис. 6.6. Оператор повторения
Оператор индексирования [ ] позволяет извлекать из строк отдельные символы или последовательности символов. Работа этого оператора не зависит от того, какие символы используются в строке. Так, на рис. 6.7 показано извлечение символов из строки цифр.
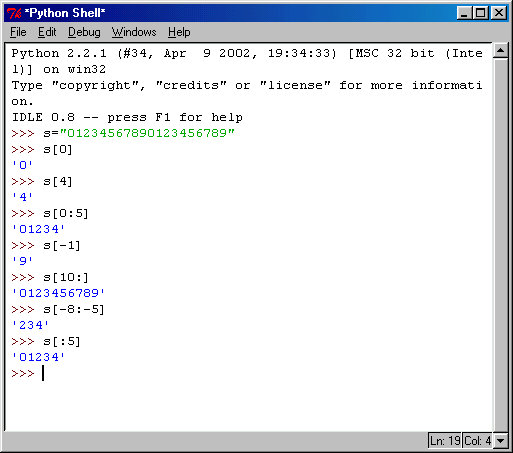
Рис. 6.7. Оператор индексирования
В отличие от многих других компьютерных языков, Python позволяет использовать отрицательную индексацию, т.е. ввод отрицательных индексов в принципе допускается, но результат будет непредсказуемым. Яркий тому пример — язык С. Для Python отрицательная индексация означает отсчёт символов в направлении от конца последовательности к началу. Ту же операцию можно выполнить более изящно: найти сначала размер последовательности, а затем вычесть из полученного значения требуемое число. Например, если нужно извлечь последний элемент строки символов, можно использовать следующую инструкцию:
е = s[len(s) - 1]
Если Вы забудете отнять единицу, то Python сообщит, что индекс вышел за границы диапазона. Автоматическое отслеживание в Python границ последовательностей — это ещё одна полезная особенность данного языка программирования. Другие языки такой информацией не владеют и безразлично реагируют на Ваши попытки возвратить элементы последовательности, которых просто не существует. Как правило, такие попытки приводят к серьёзным ошибкам в ходе выполнения программы, которые довольно сложно обнаружить и исправить в коде программы. Подобные ошибки случаются настолько часто, что Гуидо посчитал своей обязанностью сделать что-то для их предупреждения.
В других языках также имеются функции, позволяющие извлекать подстроки (части строк символов), но ни один из них не предоставляет столько удобств, как Python. (Что-то подобное умеет делать и Perl, но лично мне его синтаксис кажется не столь очевидным.) Примите к сведению, что для индексирования элементов и извлечения подстрок можно использовать не только любые целые числа, но и любые целочисленные переменные, что позволяет программно управлять размером извлекаемых подстрок.
Если оператор индексирования открывает доступ к элементам последовательности, то нельзя ли с его помощью выполнять присвоение значений элементам последовательности? Ответ однозначный — нет. Символьные строки являются неизменяемыми, Вы не можете изменять их после того, как создали. Это означает, что категорически запрещаются действия, подобные следующему:
s = "Where is misstake in this string."
s[-10] = 'н'
Python будет бурно возмущаться, если Вы попытаетесь подсунуть ему подобный код.
*Прим. В. Шипкова: это также справедливо и для версии 2.4.1
Способ, позволяющий изменить строку символов, состоит не в том, чтобы изменить её (вот Вам и немного дзен-философии), а в том, чтобы создать новую. В приведённом выше примере ошибку можно исправить следующим образом:
s="Where is misstake in this string."
s1=s[:-10]
s2=s[-9:]
s=s1+'н'+s2
Выполнение этого кода в окне IDLE показано на рис. 6.8.

Рис. 6.8. Изменение строки
Последние средства обработки последовательностей - функции min() и mах(). Эти функции извлекают из любой последовательности, переданной им в аргументе, соответственно самый маленький или самый большой элементы. При работе со строками символов минимальный и максимальный элементы однозначно определяются алфавитным порядком следования символов. Другими словами, буква А "меньше" буквы В. Другие операторы сравнения, с которыми мы сталкивались раньше, работают по тому же принципу. Если быть более точным, то определяющим является порядок следования символов в копировочной таблице компьютера, где для символов букв соблюдается алфавитный порядок. Но с помощью данных функций и операторов сравнения можно сравнивать также символы, не относящиеся к буквам алфавита, либо символы, относящиеся к разным алфавитам. Так, латинские буквы всегда "меньше" букв кириллицы. В отличие от других языков в Python могут непосредственно сравниваться ещё и строки целиком. Поэтому вполне допустимы выражения следующего вида:
if "Сергей" > "Олег" :
инструкции
Сравнение переменных, содержащих строки символов, правомерно, как и сравнение переменных, содержащих числа. При этом всегда следует помнить, что прописные буквы в таблице ASCII всегда "меньше" строчных, иначе Вы можете получить результаты, которые сильно поразят Вас. Один из методов обойти подобные неожиданности состоит в том, чтобы всегда сравнивать строчные буквы, используя метод string.lower)) для приведения всех алфавитных символов к нижнему регистру.
Пришло время ещё раз рассмотреть оператор in, с которым мы уже познакомились в главе 4. В Python цикл for не подчиняется тем же самым правилам, которые установлены в других языках программирования. Его синтаксис имеет следующий вид:
for <целевая_перененная> in <список> :
инструкции
else:
инструкции "выполняются только в том случае,
если цикл не был прервав оператором break"
Так вот, в качестве компонента <список> может использоваться любая последовательность. Поскольку строки символов являются последовательностями, то мы вправе использовать их в операторах for. Предположим, что в программе допускается ввод пользователем пути к файлу и нам необходимо удостовериться, что эта строка представляет собой допустимое описание пути в системе DOS. На рис. 6.9 демонстрируется простой способ выполнения такой проверки.

Рис. 6.9. Проверка правильности пути DOS
Если Вы внимательно проанализируете задачу, то придёте к выводу, что особой необходимости в применении цикла for тут нет. Простого теста на принадлежность-непринадлежность было бы достаточно. Тем не менее применение цикла for довольно часто оказывается полезным, а в данном случае мы просто рассмотрели пример его использования.
Вам могут понадобиться ещё и другие средства преобразования строк, например преобразование символа в число, но для выполнения подобных действий используются не операторы, а специальные функции, определённые в модуле string. Чтобы использовать данный модуль, его следует импортировать где-то в начале (лучше в самом начале) кода программы. В табл. 6.3 приведены наиболее важные и широко используемые функции обработки строк из модуля string.
Таблица 6.3. Основные функции обработки строк
Функция
Описание
atoi(s[,base])
Преобразовывает s в целое число, используя необязательный параметр base для установки основания системы счисления (по умолчанию — 10). Возвращает целое число
atol(s[,base]) Преобразовывает s в длинное целое число, используя необязательный параметр base как основание системы счисления. Возвращает длинное целое число atof(s) Преобразовывает s в число с плавающей запятой (s может содержать показатель степени). Возвращает число с плавающей запятой split(s[,sep[,maxsplit]]) Просматривает s в поисках символов, указанных в sep, и разбивает s на слова. Возвращает список слов. Если аргумент sep не указан, его значением по умолчанию является пробел. Если присутствует параметр maxsplit, то количество разбиений на слова ограничено этим числом, причём последнее слово в возвращаемом списке будет содержать оставшуюся неразбитую часть s
join(words[,sep])
Объединяет все слова списка в одну строку символов, при этом слова отделяются друг от друга символом, указанным в sep. Полученная таким образом строка и возвращается. Если параметр sep отсутствует, по умолчанию символом разбиения устанавливается пробел
find(s,sub[,start[,end]]) Просматривает s в поисках символа, указанного в sub. Если находит, возвращает индекс первого символа sub, обнаруженного в s. Параметры start и end необязательны, но если присутствуют, то start является индексом, указывающим в строке s точку начала поиска, a end является индексом, указывающим в строке точку окончания поиска Программа Ibm.py, приведенная в листинге 6.3, демонстрирует применение некоторых из этих функций. Эту программу я написал, чтобы упорядочить свою коллекцию видеофильмов. Я пронумеровал свои ленты в шестнадцатеричном формате, начиная с кассеты под номером 0000 (мой шурин считает, что это проявление окончательного помешательства под влиянием компьютеров, но, видимо, я уже не могу мыслить иначе). У меня есть небольшой принтер для печати этикеток, поэтому я могу позволить себе удовольствие напечатать самоклеющиеся этикетки для футляров кассет. Я могу распечатать целую стопку за один раз, обеспечив при этом соблюдение опредёленного формата в соответствии с шаблоном, сохраненным в текстовом файле. Приведенная ниже программа выводит на печать числа в нужном формате, либо по одному за один раз, либо начиная с номера, указанного в виде параметра в командной строке. Сначала просмотрите эту программу сами, а затем мы подробно её обсудим.
Листинг 6.3. Программа Ibm.py
#!с:\python\python.exe
import sys
import string
def printlabel(n):
s="%04X"%(n)
sys.stdout.write("%s\r\n"%(s))
for i in s :
sys.stdout.write("%s\r\n"%(i))
sys.stdout.write("\r\n")
sys.stdout.flush()
if __name__ == "__main__":
if len(sys.argv)>1:
if sys.argv[1]=="-h":
print """Usage: Ibm start_number quantity
Example:
lbm ЬЗО 100
Start_number is hex, quantity is decimal
if no arguments are given, Ibm reads from
stdin."""
sys.exit ( 0 )
elif len (sys.argv)>2:
n = string.atoi ( sys.argv[ 1 ], 0x10 )
e = string.atoi ( sys.argv[ 2 ] )
for n in range ( n, n+e ) :
printlabel(n)
else:
while 1:
p=sys.stdin.readline( )
if not p:
break
n=string.atoi(p, 0x10)
printlabel ( n )
*Прим. В. Шипкова: вразумительного ответа от этого примера Вы скорей всего не добьётесь, так как печать сообщений происходит в стандартный поток. Но тем не менее заменив все выводы sys.stdout на print можно посмотреть, что будет. ;-)
Функция printlabel() принимает целочисленный аргумент n, который сначала преобразовывается в строку шестнадцатеричных символов (инструкции, содержащие %04Х, мы рассмотрим подробно в главе 8), после чего особым образом выводится результат (sys.stdout.write()). Затем запускается цикл for i in s (здесь s является последовательностью), который записывает каждую шестнадцатеричную цифру в своей собственной строке, а в конце вставляет пустую строку. В главной части программы (часть кода, которая следует после инструкции if __name__...) выполняется проверка ввода пользователем каких-либо параметров при запуске программы. Если параметры присутствуют, то программа считывает первый параметр как шестнадцатеричное значение (инструкция n = string.atoi (sys.argv [1], 0x10)) и второй параметр — как десятичное число (инструкция e=string.atoi (sys.argv [2])). Только после этого для каждого числа, принадлежащего диапазону, указанному пользователем (инструкция for n in range (n, n + e):), вызывается функция printlabelf). Надеюсь, Вы не забыли, что 0x10 — это шестнадцатеричное число, а 16 — десятичное.
Если при запуске программы параметры отсутствуют, то Ibm.py предоставляет возможность пользователю вводить числа в шестнадцатеричном виде. Каждый номер, который получается таким образом, программа выводит на печать с помощью функции printlabel(). Наилучший способ понять, как работает эта программа, состоит в том, чтобы проверить её в работе (как и в отношении любой программы, приведенной здесь, Вы можете загрузить её с Web-страницы данной книги). Введите в командной строке каталога, в котором Вы сохранили данную программу (безусловно, под именем Ibm.py), следующую команду:
python Ibm.py > out.txt
Затем введите одно или несколько шестнадцатеричных чисел и нажмите комбинацию клавиш <Ctrl+Z>, которая прервет работу Python (<Ctrl+D> — для UNIX). Откройте и просмотрите полученный файл out.txt.
Чтобы больше узнать о модуле обработки строк и его функциях, обратитесь к документации, на Python, которую можно найти и загрузить по адресу http://www.Python.org.
Теперь, после того как мы столь тщательно рассмотрели строки символов, со следующим типом данных у Вас не должно возникнуть никаких проблем. Наборы (tuples) представляют собой другую разновидность неизменяемых последовательностей, но они более масштабные по сравнению с обычными строками символов. В строках последовательность состоит из отдельных символов, тогда как в наборах в качестве отдельных элементов могут выступать строки символов, числа любого типа, другие наборы, в общем, любая разновидность данных любого допустимого типа. Сюда входят и определяемые пользователем типы данных, которые будут рассмотрены в части III. В действительности Вы уже сталкивались с наборами ранее в этой книге. Данный раздел поможет закрепить и систематизировать ваши знания.
*Прим. В. Шипкова: также наборы в различных источниках могут упоминаться как кортежи.
Наборы заключаются в круглые скобки и так же, как и строки символов, неизменяемы. Следующий пример показывает, как сообщить Python, что некоторая переменная является набором:
t=("Это", "набор", "из", 5, "элементов.")
е=() # Это пустой набор
Подобно другим последовательностям, в кортежах можно использовать индексацию: u=t[-l]
*Прим. В. Шипкова: вот пожалуйста. Вместо слова набор используется слово кортеж.
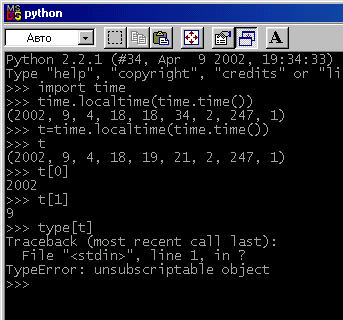
Однако, в отличие от строк, для работы с кортежами отсутствуют какие-либо специальные функции. Нет никакого модуля tuple, который можно было бы импортировать. Тем не менее многие функции возвращают результат в виде набора. Прекрасные примеры тому — функции времени и даты. На рис. 6.10 показано несколько примеров использования функции времени и приёмы работы с наборами.

Рис. 6.10. Функция времени возвращает набор значений
Python обладает прекрасным качеством, которым могут похвастать немногие языки программирования. Заключается оно в умении "распаковывать" наборы, т.е. извлекать содержащиеся в нем значения и присваивать их переменным. В примере, показанном на рис. 6.10, мы присвоили переменной t результат выполнения функции localtime (), а затем проверили тип этой переменной. Python показал, что это переменная типа tuple (набор). Примеры простых, но очень полезных операций, которые можно выполнять с наборами, показаны на рис. 6.11.
Единственное необходимое условие состоит в том, что количество отделённых запятыми переменных, стоящих слева от оператора присваивания (=), должно соответствовать числу элементов в наборе, возвращённом функцией localtime(). Если нужно извлечь только значение года, можно поступить так, как показано на рис. 6.12.

Рис. 6. 11. Извлечение значений из набора
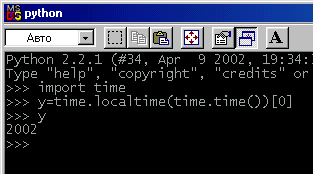
Рис. 6.12. Извлечение значения года
В данном случае распаковка всего набора не производится, а извлечение требуемого значения выполняется с помощью оператора индексирования. Функция time.time() возвращает время в виде количества секунд, отсчитанных с 1 января 1970 года. Это значение выражено в формате числа с плавающей запятой. Функция time.localtime() принимает это число с плавающей запятой в качестве аргумента и возвращает набор из 9 элементов, что мы и наблюдали на рис. 6.11. Во втором примере мы извлекаем из набора элемент с индексом [0] (год) и присваиваем значение переменной у. Этот пример демонстрирует, что любой набор (как и любая другая последовательность) может быть индексирован. А оператор индексирования можно использовать не только с самими последовательностями, но и с функциями, которые их возвращают.
Как и в случае со строками, единственный способ, с помощью которого можно изменить набор, состоит в создании нового набора. Например, если необходимо изменить год в наборе значений времени, следует поступить так, как показано на рис. 6.13.

Рис. 6.13. Изменение значения в наборе
Но есть ещё более простой способ, который состоит в том, чтобы использовать конкатенацию строки символов в сочетании с извлечением части строки: yt = (1888,) + u[l:8]
Так как в Python очень просто перепутать число, заключенное в круглые скобки, (1888), с набором, содержащим единственный элемент, то добавление запятой после значения (1888,) является единственным способом указать Python, что речь идёт именно о наборе. Запятая в данном случае служим условным ключом, сигнализирующим, что это набор. Извлечение части строки, показанное как u[1:8], сообщает Python, что мы хотим извлечь все элементы набора, начиная со 2-го по 9-й. Затем используется оператор конкатенации, чтобы объединить два набора в один.
Имеется, правда, ещё более простой метод, который предоставляет Вам широкие возможности для внесения в последовательности всевозможных изменений. А состоит он в использовании списков, но это уже тема следующего раздела.
Списки во многом очень похожи на наборы, за исключением того, что они являются изменяемыми последовательностями. Кроме того, списки владеют методами. Методы почти полностью походят на функции, за исключением того, что они всегда принадлежат некоторому типу данных. Вспомните, что ранее мы уже встречались с идентификаторами модулей, когда нужно было вызвать принадлежащую им функцию. Пример такого идентификатора— вызов функции time.time(), где мы указываем Python, что функция time() принадлежит модулю time. Чтобы вызывать методы, необходимо также сообщать Python тип данных, которому принадлежит данный метод. Единственное отличие состоит в том, что для вызова функций модулей используются одни идентификаторы, а для вызова методов — другие.
Вы можете сообщить Python, что переменная является списком, заключив значения в квадратные скобки вместо круглых:
t = ["Это", "список", "из", 5, "элементов."]
е = [] # Это пустой список
Пример использования списка показан на рис. 6.14. Обратите внимание на отличие между наборами и списками.

Рис. 6.14. Использование списка
Как видите, изменить список намного проще, чем набор. Также легко преобразовать набор в список, просто воспользовавшись функцией list(). Списки, в силу их изменяемости и функциональности, часто являются самым предпочтительным типом данных. Наборы удобно применять в тех случаях, когда изменение данных не предполагается и их следует защитить от случайного изменения. Кроме того, наборы в Python занимают меньше памяти. Для небольших программ, безусловно, потребление памяти не является критичным фактором. Тем не менее всегда следует стремиться к достижению максимальной эффективности, что окажется для Вас полезной привычкой во время работы над действительно большим проектом.
Списки, как я уже говорил, содержат методы. Вот они-то как раз и определяют функциональность списков, что делает их чрезвычайно привлекательными средствами программирования. В табл. 6.4 приведены все методы, доступные для использования со списками.
Таблица 6.4. Методы, применяемые к спискам
Метод Описание Пример append(s) Добавляет s в конец списка 1.append( "элемент") count(s) Подсчитывает, сколько раз в списке встречается s 1.count("элемент") index(s) Определяет в списке индекс элемента s 1.index("элемент") insert(i,s) Вставляет в список s по месту, указанному индексом i 1.insert(2,"элемент") remove(s) Удаляет из списка первый встреченный экземпляр s 1.remove("элемент") reverse() Изменяет порядок следования элементов в списке на противоположный 1.reverse() sort([имя_функции])
Сортирует список в порядке возрастания. Необязательный аргумент имя функции является именем функции сортировки (см. пояснения в тексте)
1.sortd
Хотя обычно в методе sort() нет необходимости использовать аргументы, иногда бывает полезно иметь возможность управлять порядком сортировки элементов списка. Именно это и позволяет делать функция сортировки, передающаяся в метод sort() в качестве аргумента. Функция сортировки в свою очередь принимает два аргумента и вызывается каждый раз при обращении к методу sort(). Упомянутые два аргумента функции представляют собой элементы списка. Вы сообщаете Python, в каком порядке следует сортировать список по значению, возвращаемому функцией сортировки (0, 1 или -1). По умолчанию задается сортировка по возрастанию. Выполнить сортировку по убыванию столь же просто:
l=["d", "e", "f", "с", "b", "а"]
l.sort()
l.reverse()
Так что для сортировки в порядке возрастания или убывания нет никакой необходимости создавать свою собственную функцию сортировки. Пример использования специальной функций сортировки показан в листинге 6.4, где функция sort() располагает все числа после строковых значений. Таким образом, функции сортировки необходимы тогда, когда требуемое упорядочивание элементов списка нельзя свести к сортировке по возрастанию или убыванию.
Листинг 6.4. Программа sort.py
#!с:\python\python.exe
l = ["а", 2,"f", "b", "е" "d", "с", 0, 5]
def srt(a, b):
if type(a) == type(0) and type(b) == type(0):
if a < b:
return -1
elif a > b:
return 1
return 0
if type(a) == type("") and type(b) == type(""):
if a < b:
return -1
elif a > b:
return 1
return 0
if type(a) == type(0) and type(b) == type(""):
return 1
if type(a) == type("") and type(b) == type(0):
return -1
return 0
print l
l.sort()
print l
l.reverse()
print l
l.sort(srt)
print l
На рис. 6.15 показано ещё несколько методов, которыми можно воспользоваться при работе со списками.
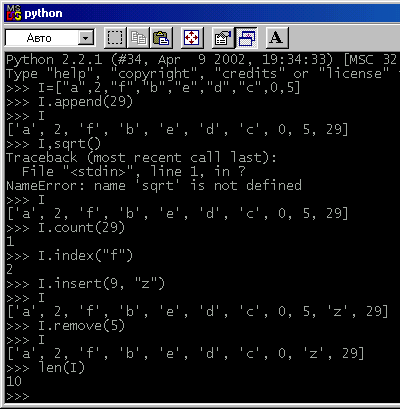
Рис. 6.15, Методы обработки списков
Списки — это последний тип данных, относящийся к последовательностям. Следующий раздел посвящен словарям, которые существенно отличаются от ранее рассмотренных типов, но являются чрезвычайно полезными и удобными в программах на языке Python.
Словари в какой-то мере подобны последовательностям, только их элементы не хранятся в каком-либо опредёленном порядке. Они представляют собой совокупности пар ключ—значение. Вы помещаете информацию в словарь, предоставляя Python ключ (в качестве которого может выступать почти любой допустимый в Python тип данных), с которым сопоставляется значение, которое, в свою очередь, также может быть представлено данными любого типа. Наиболее распространённым типом ключа являются строки, но допускается использовать и целые числа, длинные целые числа и наборы. В качестве ключей нельзя применять только списки и словари. Ключ является неизменяемым элементом словаря, поэтому удобно в качестве ключей использовать константные, или вычисляемые значения, которые затем преобразуются в константные типы данных. Цифры, используемые в программном коде, являются константами, поскольку выражения типа 1 = 2 воспринимаются Python как ошибки.
Вот способ создания пустого словаря:
diet = {}
Признаком словаря в Python служат фигурные скобки, даже если между ними ничего не заключено. Присвоить пустому словарю первый элемент, состоящий из значения и ключа, можно следующим образом:
dict["mypi"] = 3.14159
В данном примере ключом будет строка mypi, а значением — число с плавающей запятой 3.14159. Чтобы извлечь значение, в качестве индекса просто применяется ключ, связанный с этим значением:
mypi = dict["mypi"]
Если указанный ключ в момент вызова ещё не существует в словаре, Python покажет сообщение об ошибке. Для создания в одной строке полноценного словаря с ключами и значениями используется следующий синтаксис:
diet={"first":1, "second":2, "third":3, "eleventh":11}
Хотя Вы можете задавать элементы словаря в опредёленном порядке, Python будет сохранять ключи и значения в произвольном, только ему известном порядке. Когда я ввёл предшествующую строку, а затем распечатал переменную diet, то вот что я получил:
{'first': 1, 'third': 3, 'eleventh': 11, 'second': 2}
*Прим. В. Шипкова: в Python 2.4.1 список выводится с точностью до наоборот.
{'second': 2, 'eleventh': 11, 'third': 3, 'first': 1}
Нет смысла заставлять Python хранить элементы словаря в каком-либо порядке. Если необходимо вывести содержимое словаря в определённой последовательности, используйте встроенный метод keys(), который отсортирует элементы словаря по ключам, как это показано на рис. 6.16.
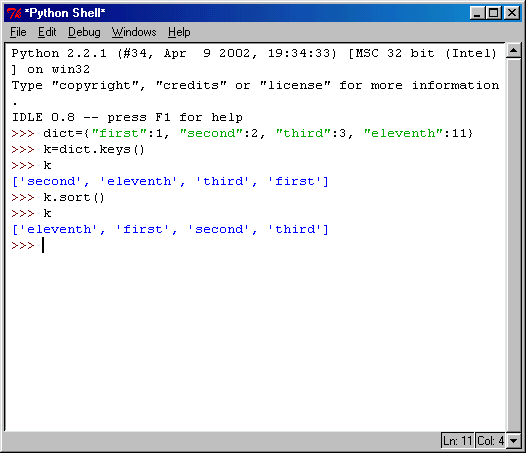
Рис. 6.16. Сортировка элементов словаря по ключам
Для работы со словарями применима большая часть операторов обработки последовательностей, за исключением операторов извлечения подстрок. Множество других полезных функций в работе над словарями можно реализовать с помощью методов. В табл. 6.5 приведён список всех методов, доступных для обработки словарей.
Таблица 6.5. Методы обработки словарей
Метод Описание Пример clear() Удаляет из словаря все элементы diet.clear() copy() Возвращает экземпляр (копию) всех элементов словаря newcopy=dict. copy() get(ключ[,по умолчанию]) ещё один метод возвращения значения по ключу, но в этом случае, если указанный ключ в словаре не обнаружен, метод возвращает None или значение, заданное по умолчанию x=dict.get ("Неправильный ключ") haskey(k) Возвращает 0, если данный ключ не существует, иначе —1 t=dict.haskey("Spam")
items () Возвращает список наборов, состоящих из пар значений (ключ, значение) для всех элементов словаря t=dict.items () keys() Возвращает список всех ключей словаря l=dict.keys() update(dict2) Обновляет словарь по образцу dict2 (см. пояснения в тексте) diet.update (dict2 values()
Возвращает список всех значений, содержащихся в словаре
v=dict.values()
Большинство приведенных методов вполне очевидны и понятны, за исключен метода update(), пример использования которого показан на рис. 6.17.

Рис. 6.17. Обновление словаря
Словари можно использовать для хранения информации любого типа, даже других словарей. Это свойство присуще также таким типам данных, как набор и список. Все они могут хранить элементы любого типа, включая данные того же самого типа, т.е. другие вложенные наборы, списки и словари. Словари особенно удобны в тех случаях, когда порядок следования элементов не имеет значения, но есть необходимость позволить пользователям извлекать данные по опредёленным ключам, которые можно вводить, например, с клавиатуры. Давайте рассмотрим такой небольшой прикладной пример. За последние 400 лет изучения календаря индейцев Майя разными учеными было предложено множество терминов для обозначения месяцев в этом календаре. Недавно были приняты стандартные названия, каждому из которых соответствует множество синонимов. Чтобы дать возможность пользователям моей программы удостовериться, соответствует ли выбранное ими название более привычному для них синониму, я разработал словарь. В этом словаре ключами являются всевозможные варианты названий месяцев календаря Майя (строки), тогда как значениями выступают порядковые номера этих месяцев в году (целые числа). Это значительно упростило пользовательский интерфейс по сравнению с аналогичной версией, которую я написал на языке С много лет назад, а также повысило эффективность и гибкость интерфейса.
Код словаря месяцев Майя показан в листинге 6.5 (в каждом списке новые стандартные названия перечислены первыми).
monthnames = {
"pohp":0, "pop":0, "kanhalaw":0, "k'anhalaw":0,
"wo":l, "uo":l, "ik'k'at":1, "ikk'at":1,
"ik'kat":1, "ikkat":1,
"sip":2, "zip":2, "chakk'at:2, "chakkat":2,
"sots":3, "zots":3, "zotz":3, "tsots":3,
1 "tzots":3, "suts":3, "suts"':3, "sutz":3, "sutz'":3,
1 "sek":4, "sec":4, "zec":4, "zek":4, "tzek":4,
1 "tsek":4, "kasew":4,
1 "xul":5, "chichin":5,
"yaxk'in":6, "yaxkin":6,
"mol":7,
"ch'en":8, "chen":8, "ik'":8, "ik":8,
"yax":9,
"sak":10, "zak":10, "tsak":10, "tzak":10,
"keh":ll, "ceh":ll, "chak":ll,
"mak":12, "mac":12,
"k'ank'in":13, "kank'in":13, "kankin":13, "uniw":13,
"muwan":14, "muan":14, "moan":14,
"pax":15, "ah k'ik'u":15, "ahk'ik'u":15, "ahkik'u":15,
"ah kik'u":15, "ahk'iku":15, "ah k'iku":15,
"ahkiku":15,
"ah kiku":15,
"k'ayab":16, "kayab":16, "cayab":16, "kanasi":16,
"k'anasi":16,
"kumk'u":17, "kumku":17, "cumku":17, "cumhu":17,
"cum'hu":17, "ol":17,
"wayeb":18, "uayeb":18
}
Словари очень удобны также при формировании так называемой таблицы рапределений, в которой по ключу определяется функция, которую необходимо вызвать. Например, в рассмотренном выше словаре месяцев Майя можно легко заменить числовые значения номера месяца на имена функций, чтобы при вводе пользователем одного из синонимов названия месяца каждый раз вызывалась соответствующая функция. Можно изменить словарь таким образом, чтобы функции вызывались только при вводе нестандартных названий месяцев и автоматически заменяли их на стандартные.
Другой благодатной почвой применения словарей является обработка выбора опций меню. Предположим, что Вы хотите предоставить пользователю на выбор множество опций. Основываясь на обычных приёмах, Вам пришлось бы создать сложную конструкцию из условных операторов, как в следующем примере:
if выбор_пользоватепя == 1:
функция1()
elif выбор_пользователя == 2:
function2()
Но благодаря применению словарей эта процедура становится значительно проще:
diet={" 1 ":функция1, " 2 ":функция2, ...}
. . . возвращение выбора пользователя любым способом — dict[user_choice] ( )
Python обладает огромным количеством модулей расширения. Документация на все модули, как стандартные так и расширения, может быть найдена на уже известном Вам сервере http://www.Python.org/. Во время установки Python я настоятельно рекомендую наряду с Python выгрузить и установить документацию в формате HTML. Иметь этот справочник всегда под рукой значительно удобнее, чем заходить каждый раз в Internet, особенно если у Вас медленная связь с провайдером и Вы оплачиваете время работы в сети. Многим из тех, кто переходит к языку Python от других языков программирования, поможет адаптироваться модуль array, который предоставляет средства обработки массивов, аналогичные языку С. Массивы во многом напоминают списки и наборы. Это изменяемый тип данных, но на их использование наложено ограничение, требующее, чтобы массивы содержали только однородные данные. Примеры использования массивов показаны на рис. 6.18.
Как Вы видите, элементы массивов можно легко изменять. Массивы символов можно преобразовать в строки символов, а также выполнять обратные преобразования с помощью метода fromstring(). В любой момент, когда Вам понадобится считать или записать двоичную информацию из файла или в файл, в Вашем распоряжении имеются превосходные методы обработки массивов. Такие задачи (а они не из самых приятных) рано или поздно приходится решать каждому программисту. Более подробную информацию можно найти в документации на массивы. ещё раз обратите внимание на один важный момент: массивы могут содержать элементы только одного типа. Это объясняется тем, что все элементы массива должны иметь один и тот же размер. Но те же ограничения иногда возникают при совмещении модулей, написанных на разных языках программирования, или при передаче данных по сети. Например, для корректной передачи данных по сети часто бывает необходимо предварительно привести все значения к шестнадцатеричному формату. В этом случае использование массивов усилит Ваш контроль за вводимыми данными.

Рис. 6.18. Использование массивов
Изучая материал данной главы, нам пришлось изрядно потрудиться. Вы познакомились с использованием строк символов, включая использование функций модуля string. Вы узнали, чем наборы отличаются от списков, и научились применять методы обработки списков, а также познакомились со словарями и их методами. Далее мы будем часто обращаться в своих программах к словарям. И наконец, мы обсудили с Вами особенности применения массивов. В следующей главе Вы научитесь определять функции. А помогут Вам в этом знания базовых типов данных, которыми Вы уже овладели.
Почему строки символов Python являются неизменяемым типом данных?
Это снизило бы эффективность работы программ на языке Python. He сложно было сделать строки символов изменяемыми, но это сильно замедлило бы работу, поскольку управление выделением памяти для изменяемых переменных происходит значительно медленнее. На практике строки используются очень часто, а необходимость в их изменении возникает довольно редко.
Используют ли словари другие языки?
Да. Их использует SNOBOL, который является языком обработки строк символов. Две программы оболочки командной строки под UNIX, bash и ksh, также используют словари, хотя в этом случае они называются ассоциативными массиВами. Словари интенсивно использует ещё один довольно скромный язык программирования — AWK, разработанный для систем UNIX. Применяются словари и в Perl, причём одним из его прототипов служил язык AWK, и во многих других языках программирования.
В каком случае все же удобно использовать наборы?
Это, безусловно, полезное средство программирования. Но учитывая небольшой размер и ограниченную функциональность большинства программ, с которыми Вы будете работать по ходу чтения этой книги, наборы практически всегда будут уступать по эффективности спискам. Преимущество наборов можно оценить только во время работы над большими проектами, когда критичным становится расход памяти компьютера. Наборы, в отличие от списков, гораздо экономичнее в смысле потребления памяти и других ресурсов. Кроме того, многие функции возвращают наборы, а не списки.
Можно ли в операторах for использовать строки символов?
а) Нет.
б) Да, но сначала необходимо обработать их с помощью функции, преобразующей их в последовательности.
в) Да, так как строки символов уже являются последовательностями.
г) Только если строки содержат последовательности цифр.
Что в словарях может быть использовано в качестве ключей?
а) Целые числа и длинные целые числа.
б) Строки символов и наборы.
в) Числа с плавающей запятой и комплексные числа.
г) Всё вышесказанное.
Что означает оператор + применительно к строкам?
а) Конкатенацию двух строк символов в одну новую.
б) Суммирование кодов ASCII всех символов обеих строк.
в) Прежде чем использовать этот оператор, его нужно предварительно переопределить в программе.
г) Объединение двух строк в одну со знаком ' + ' между ними.
Что такое идентификаторы?
а) Средства проверки уровня безопасности ваших программ.
б) Функции, которые используют для преобразования массивов символов в строки.
в) Средство указания полного имени функции, включая имя модуля. Применение идентификаторов позволяет избежать возникновение конфликтов имён.
г) Средства, обеспечивающие переносимость программ на языке Python между разными платформами.
в. Строки символов являются последовательностями, поэтому вполне допустимо (а часто и полезно) их использование в операторах for.
г. В словарях в качестве ключей можно использовать все указанные типы данных. Нельзя использовать только списки, словари и объекты, определяемые пользователем.
а. Оператор + выполняет конкатенацию двух строк для создания новой строки.
в. Идентификаторы используют для указания полного имени функции, включая имя модуля, что позволяет избежать возникновения конфликтов имён.
Чтобы лучше подготовиться к темам, которые мы будем рассматриваться в следующих главах, ещё раз просмотрите код программы Ibm.py (листинг 6.3) и проверьте, сможете ли Вы объяснить, что именно выполняет каждая строка кода, в том числе и те из них, которые мы не рассматривали. В случае возникновения затруднений внимательно пересмотрите документацию на Python, выгружаемую из Internet в формате HTML. Сможете ли Вы переписать программу lbm.py так, чтобы она состояла из меньшего количества строк кода? Сокращать код — один из лучших приёмов научиться программированию. Естественно, что сокращение кода не должно сопровождаться потерей функциональности программы. Вам часто на практике придётся выполнять эту задачу. Исходные коды программы обычно оказываются неоправданно длинными из-за того, что программист сохраняет на всякий случай свои промежуточные наработки, которые затем нигде не используются и лишь захламляют код. И это в лучшем случае. Часто в этом хламе заводятся "жучки", которые вызывают ошибки в работе программы и затрудняют их поиск во время отладки. Поэтому имеет смысл время от времени "прочёсывать" весь код и избавляться от всякой чепухи, в которой Вы больше не нуждаётесь.